Особое значение имеет расчет множественного коэффициента корреляции результативного признака y с факторными x 1 , x 2 ,…, x m , формула для определения которого в общем случае имеет вид
где ∆ r – определитель корреляционной матрицы; ∆ 11 – алгебраическое дополнение элемента r yy корреляционной матрицы.
Если рассматриваются лишь два факторных признака, то для вычисления множественного коэффициента корреляции можно использовать следующую формулу:

Построение множественного коэффициента корреляции целесообразно только в том случае, когда частные коэффициенты корреляции оказались значимыми, и связь между результативным признаком и факторами, включенными в модель, действительно существует.
Коэффициент детерминации
Общая формула: R 2 = RSS/TSS=1-ESS/TSSгде RSS - объясненная сумма квадратов отклонений, ESS - необъясненная (остаточная) сумма квадратов отклонений, TSS - общая сумма квадратов отклонений (TSS=RSS+ESS)
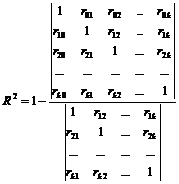 ,
,
где r ij - парные коэффициенты корреляции между регрессорами x i и x j , a r i 0 - парные коэффициенты корреляции между регрессором x i и y ;
- скорректированный (нормированный) коэффициент детерминации.
Квадрат множественного коэффициента корреляции ![]() называется множественным коэффициентом детерминации
; он показывает, какая доля дисперсии результативного признака y
объясняется влиянием факторных признаков x 1 , x 2 , …,x m . Заметим, что формула для вычисления коэффициента детерминации через соотношение остаточной и общей дисперсии результативного признака даст тот же результат.
называется множественным коэффициентом детерминации
; он показывает, какая доля дисперсии результативного признака y
объясняется влиянием факторных признаков x 1 , x 2 , …,x m . Заметим, что формула для вычисления коэффициента детерминации через соотношение остаточной и общей дисперсии результативного признака даст тот же результат.
Множественный коэффициент корреляции и коэффициент детерминации изменяются в пределах от 0 до 1. Чем ближе к 1, тем связь сильнее и, соответственно, тем точнее уравнение регрессии, построенное в дальнейшем, будет описывать зависимость y
от x 1 , x 2 , …,x m . Если значение множественного коэффициента корреляции невелико (меньше 0,3), это означает, что выбранный набор факторных признаков в недостаточной мере описывает вариацию результативного признака либо связь между факторными и результативной переменными является нелинейной.
Рассчитывается множественный коэффициент корреляции с помощью калькулятора . Значимость множественного коэффициента корреляции и коэффициента детерминации проверяется с помощью критерия Фишера .
Какое из приведенных чисел может быть значением коэффициента множественной детерминации:
а) 0,4 ;
б) -1;
в) -2,7;
г) 2,7.
Множественный линейный коэффициент корреляции равен 0.75 . Какой процент вариации зависимой переменной у учтен в модели и обусловлен влиянием факторов х 1 и х 2 .
а) 56,2 (R 2 =0.75 2 =0.5625);
Министерство образования и науки российской федерации
Федеральное государственное автономное образовательное учреждение высшего профессионального образования
Дальневосточный федеральный университет
Школа экономики и менеджмента
Кафедра бизнес-информатики и экономико-математических методов
ЛАБОРАТОРНАЯ РАБОТА
по дисциплине «Имитационное моделирование»
Специальность 080801.65 «Прикладная информатика (в экономике)»
РЕГРЕССИОННЫЙ АНАЛИЗ
Рудакова
Ульяна Анатольевна
г. Владивосток
ОТЧЕТ
Задание: рассмотреть процедуру регрессионного анализа на основе данных (цена продажи и жилая площадь) о 23 объектах недвижимости.
Режим работы "Регрессия" служит для расчета параметров уравнения линейной регрессии и проверки его адекватности исследуемому процессу.
Для решения задачи регрессионного анализа в MS Excel выбираем в меню Сервис
команду Анализ данных
и инструмент анализа "Регрессия
".
В появившемся диалоговом окне задаем следующие параметры: 1.
Входной интервал Y
- это диапазон данных по результативному признаку. Он должен состоять из одного столбца.
2.
Входной интервал X
- это диапазон ячеек, содержащих значения факторов (независимых переменных). Число входных диапазонов (столбцов) должно быть не больше 16.
.Флажок Метки
, устанавливается втом случае, если в первой строке диапазона стоит заголовок.
5.
Константа ноль.
Данный флажок необходимо установить, если линия регрессии должна пройти через начало координат (а0=0).
6.
Выходной интервал/ Новый рабочий лист/ Новая рабочая книга -
указать адрес верхней левой ячейки выходного диапазона.
.Флажки
в группе Остатки
устанавливаются, если необходимо включить в выходной диапазон соответствующие столбцы или графики.
.Флажок График нормальной вероятности необходимо сделать активным, если требуется вывести на лист точечный график зависимости наблюдаемых значений Y от автоматически формируемых интервалов персентилей.
После нажатия кнопки ОК в выходном диапазоне получаем отчет. С помощью набора средств анализа данных выполним регрессионный анализ исходных данных. Инструмент анализа "Регрессия" применяется для подбора параметров уравнения регрессии с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или нескольких независимых переменных. ТАБЛИЦА РЕГРЕССИОННАЯ СТАТИСТИКА Величина множественный R
- это корень из коэффициента детерминации (R-квадрат). Также его называют индексом корреляции или множественным коэффициентом корреляции. Выражает степень зависимости независимых переменных (X1, X2) и зависимой переменной (Y) и равен квадратному корню из коэффициента детерминации, эта величина принимает значения в интервале от нуля до единицы. В нашем случае он равен 0,7, что говорит о существенной связи между переменными.
Величина R-квадрат (коэффициент детерминации)
, называемая также мерой определенности, характеризует качество полученной регрессионной прямой. Это качество выражается степенью соответствия между исходными данными и регрессионной моделью (расчетными данными). Мера определенности всегда находится в пределах интервала .
В нашем случае величина R-квадрат равна 0,48 , т.е. почти 50%, что говорит о слабой подгонке регрессионной прямой к исходным данным.Т.к. найденная величина R-квадрат = 48%<75%, то, следовательно, также можно сделать вывод о невозможности прогнозирования с помощью найденной регрессионной зависимости. Таким образом, модель объясняет всего 48% вариации цены, что говорит о недостаточности выбранных факторов, либо о недостаточном объеме выборки. Нормированный R-квадрат
- это тот же коэффициент детерминации, но скорректированный на величину выборки.
Норм.R-квадрат=1-(1-R-квадрат)*((n-1)/(n-k)), регрессионный анализ линейный уравнение где n - число наблюдений; k - число параметров. Нормированный R-квадрат предпочтительнее использовать в случае добавления новых регрессоров (факторов), т.к. при их увеличении будет также увеличиваться значение R-квадрат, однако это не будет свидетельствовать об улучшении модели. Так как в нашем случае полученная величина равна 0,43 (что отличается от R-квадрат всего на 0,05), то можно говорить о высоком доверии коэффициенту R-квадрат. Стандартная ошибка
показывает качество аппроксимации (приближения) результатов наблюдений. В нашем случае ошибка равна 5,1. Рассчитаем в процентах: 5,1/(57,4-40,1)=0,294 ≈ 29% (Модель считается лучше, когда стандартная ошибка составляет <30%)
Наблюдения
- указывается число наблюдаемых значений (23).
ТАБЛИЦА ДИСПЕРСИОННЫЙ АНАЛИЗ Для получения уравнения регрессии определяется -статистика - характеристика точности уравнения регрессии, представляющая собой отношение той части дисперсии зависимой переменной которая объяснена уравнением регрессии к необъясненной (остаточной) части дисперсии. В столбце df
- приводится число степеней свободы k. Для остатка это величина, равная n-(m+1), т.е. число исходных точек (23) минус число коэффициентов (2) и минус свободный член (1). В столбце SS
- суммы квадратов отклонений от среднего значения результирующего признака. В нем представлены: Регрессионная сумма квадратов отклонений от среднего значения результирующего признака теоретических значений, рассчитанных по регрессионному уравнению. Остаточная сумма отклонений исходных значений от теоретических значений. Общая сумма квадратов отклонений исходных значений от результирующего признака. Чем больше регрессионная сумма квадратов отклонений (или чем меньше остаточная сумма), тем лучше регрессионное уравнение аппроксимирует облако исходных точек. В нашем случае остаточная сумма составляет около 50%. Следовательно, уравнение регрессии очень слабо аппроксимирует облако исходных точек. В столбце MS
- несмещенные выборочные дисперсии, регрессионная и остаточная. В столбце F
вычислено значение критериальной статистики для проверки значимости уравнения регрессии. Для осуществления статистической проверки значимости уравнения регрессии формулируется нулевая гипотеза об отсутствии связи между переменными (все коэффициенты при переменных равны нулю) и выбирается уровень значимости. Уровень значимости - это допустимая вероятность совершить ошибку первого рода - отвергнуть в результате проверки верную нулевую гипотезу. В рассматриваемом случае совершить ошибку первого рода означает признать по выборке наличие связи между переменными в генеральной совокупности, когда на самом деле ее там нет. Обычно уровень значимости принимается равным 5%. Сравнивая полученное значение = 9,4 с табличным значением = 3,5 (число степеней свободы 2 и 20 соответственно) можно говорить о том, что уравнение регрессии значимо (F>Fкр). В столбце значимость F
вычисляется вероятность полученного значения критериальной статистике. Так как в нашем случае это значение = 0,00123, что меньше 0,05 то можно говорить о том, что уравнение регрессии (зависимость) значимо с вероятностью 95%. Два выше описанных столба показывают надежность модели в целом. Следующая таблица содержит коэффициенты для регрессоров и их оценки. Строка Y-пересечение не связана ни с каким регрессором, это свободный коэффициент. В столбце
коэффициенты
записаны значения коэффициентов уравнения регрессии. Таким образом, получилось уравнение:
Y=25,6+0,009X1+0,346X2
Регрессионное уравнение должно проходить через центр облака исходных точек: 13,02≤M(b)≤38,26 Далее сравниваем попарно значения столбцов Коэффициенты и Стандартная ошибка.
Видно, что в нашем случае, все абсолютные значения коэффициентов превосходят значения стандартных ошибок. Это может свидетельствовать о значимости регрессоров, однако, это грубый анализ. Столбец t-статистика содержит более точную оценку значимости коэффициентов. В столбце t-статистика
содержатся значения t-критерия, рассчитанные по формуле:
t=(Коэффициент)/(Стандартная ошибка)
n-(k+1)=23-(2+1)=20
По таблице Стьюдента находим значение tтабл=2,086. Сравнивая t с tтабл получаем, что коэффициент регрессора X2 незначим. Столбец p-значение
представляет вероятность того, что критическое значение статистики используемого критерия (статистики Стьюдента) превысит значение, вычисленное по выборке. В данном случае сравниваем p-значения
с выбранным уровнем значимости (0.05). Видно, что незначимым можно считать только коэффициент регрессора X2=0.08>0,05 В столбцах нижние 95% и верхние 95% приводятся границы доверительных интервалов с надежностью 95%. Для каждого коэффициента свои границы: Коэффициент
tтабл*Стандартная ошибка
Доверительные интервалы строятся только для статистически значимых величин. ТАБЛИЦА ВЫВОД ОСТАТКА Остаток
- это отклонение отдельной точки (наблюдения) от линии регрессии (предсказанного значения). Предположение о нормальности остатков
допускает, что распределение разницы предсказанных и наблюдаемых значений является нормальным. Для визуального определения характера распределения включаем функцию график остатков
. На графиках остатков отображаются разности между исходными значениями Y и вычисленными по функции регрессии для каждого значения компонента переменной X1 и X2. Он применяется для определения, является ли приемлемой используемая аппроксимирующая прямая. График подбора может быть использован для получения наглядного представления о линии регрессии. Стандартные остатки - нормированные остатки на оценку их стандартного отклонения.
ВЫВОД ИТОГОВ
| Регрессионная статистика | |
| Множественный R | 0,998364 |
| R-квадрат | 0,99673 |
| Нормированный R-квадрат | 0,996321 |
| Стандартная ошибка | 0,42405 |
| Наблюдения | 10 |
Сначала рассмотрим верхнюю часть расчетов, представленную в таблице 8.3а , - регрессионную статистику.
Величина R-квадрат , называемая также мерой определенности, характеризует качество полученной регрессионной прямой. Это качество выражается степенью соответствия между исходными данными и регрессионной моделью (расчетными данными). Мера определенности всегда находится в пределах интервала .
В большинстве случаев значение R-квадрат находится между этими значениями, называемыми экстремальными, т.е. между нулем и единицей.
Если значение R-квадрата близко к единице, это означает, что построенная модель объясняет почти всю изменчивость соответствующих переменных. И наоборот, значение R-квадрата , близкое к нулю, означает плохое качество построенной модели.
В нашем примере мера определенности равна 0,99673, что говорит об очень хорошей подгонке регрессионной прямой к исходным данным.
Множественный R - коэффициент множественной корреляции R - выражает степень зависимости независимых переменных (X) и зависимой переменной (Y).
Множественный R равен квадратному корню из коэффициента детерминации, эта величина принимает значения в интервале от нуля до единицы.
В простом линейном регрессионном анализе множественный R равен коэффициенту корреляции Пирсона. Действительно, множественный R в нашем случае равен коэффициенту корреляции Пирсона из предыдущего примера (0,998364).
| Коэффициенты | Стандартная ошибка | t-статистика | |
| Y-пересечение | 2,694545455 | 0,33176878 | 8,121757129 |
| Переменная X 1 | 2,305454545 | 0,04668634 | 49,38177965 |
| * Приведен усеченный вариант расчетов | |||
Теперь рассмотрим среднюю часть расчетов, представленную в таблице 8.3б . Здесь даны коэффициент регрессии b (2,305454545) и смещение по оси ординат, т.е. константа a (2,694545455).
Исходя из расчетов, можем записать уравнение регрессии таким образом:
Y= x*2,305454545+2,694545455
Направление связи между переменными определяется на основании знаков (отрицательный или положительный) коэффициентов регрессии (коэффициента b).
Если знак при коэффициенте регрессии - положительный, связь зависимой переменной с независимой будет положительной. В нашем случае знак коэффициента регрессии положительный, следовательно, связь также является положительной.
Если знак при коэффициенте регрессии - отрицательный, связь зависимой переменной с независимой является отрицательной (обратной).
В таблице 8.3в . представлены результаты вывода остатков . Для того чтобы эти результаты появились в отчете, необходимо при запуске инструмента "Регрессия" активировать чекбокс "Остатки".
ВЫВОД ОСТАТКА
| Наблюдение | Предсказанное Y | Остатки | Стандартные остатки |
|---|---|---|---|
| 1 | 9,610909091 | -0,610909091 | -1,528044662 |
| 2 | 7,305454545 | -0,305454545 | -0,764022331 |
| 3 | 11,91636364 | 0,083636364 | 0,209196591 |
| 4 | 14,22181818 | 0,778181818 | 1,946437843 |
| 5 | 16,52727273 | 0,472727273 | 1,182415512 |
| 6 | 18,83272727 | 0,167272727 | 0,418393181 |
| 7 | 21,13818182 | -0,138181818 | -0,34562915 |
| 8 | 23,44363636 | -0,043636364 | -0,109146047 |
| 9 | 25,74909091 | -0,149090909 | -0,372915662 |
| 10 | 28,05454545 | -0,254545455 | -0,636685276 |
При помощи этой части отчета мы можем видеть отклонения каждой точки от построенной линии регрессии. Наибольшее абсолютное значение
7.1. Линейный регрессионный анализ
заключается в подборе графика для набора наблюдений с помощью метода наименьших квадратов. Регрессионный анализ позволяет установить функциональную зависимость между некоторой случайной величиной Y
и некоторыми влияющими на Y
величинами X
. Такая зависимость получила название уравнения регрессии. Различают простую (y=m*x+b
) и множественную (y=m 1 *x 1 +m 2 *x 2 +... + m k *x k +b
) регрессию линейного и нелинейного типа.
Для оценки степени связи между величинами используется коэффициент множественной корреляции R Пирсона
(корреляционное отношение), который может принимать значения от 0 до 1. R
=0, если между величинами нет никакой связи, и R
=1, если между величинами имеется функциональная связь. В большинстве случаев R принимает промежуточные значения от 0 до 1. Величина R 2
называется коэффициентом детерминации
.
Задачей построения регрессионной зависимости является нахождение вектора коэффициентов M
модели множественной линейной регрессии, при котором коэффициент R
принимает максимальное значение.
Для оценки значимости R
применяется F-критерий Фишера
, вычисляемый по формуле:
Где n – количество экспериментов; k – число коэффициентов модели. Если F превышает некоторое критическое значение для данных n и k и принятой доверительной вероятности, то величина R считается существенной.
7.2. Инструмент Регрессия из Пакета анализа позволяет вычислить следующие данные:
· коэффициенты линейной функции регрессии – методом наименьших квадратов; вид функции регрессии определяется структурой исходных данных;
· коэффициент детерминации и связанные с ним величины (таблица Регрессионная статистика );
· дисперсионную таблицу и критериальную статистику для проверки значимости регрессии (таблица Дисперсионный анализ );
· среднеквадратическое отклонение и другие его статистические характеристики для каждого коэффициента регрессии , позволяющие проверить значимость этого коэффициента и построить для него доверительные интервалы;
· значения функции регрессии и остатки – разности между исходными значениями переменной Y и вычисленными значениями функции регрессии (таблица Вывод остатка );
· вероятности, соответствующие упорядоченным по возрастанию значениям переменной Y (таблица Вывод вероятности ).
7.3. Вызовите инструмент создания выборки через Данные> Анализ данных> Регрессия .

7.4. В поле Входной интервал Y
вводится адрес диапазона, содержащего значения зависимой переменной Y. Диапазон должен состоять из одного столбца.
В поле Входной интервал X
вводится адрес диапазона, содержащего значения переменной X. Диапазон должен состоять из одного или нескольких столбцов, но не более чем из 16 столбцов. Если указанные в полях Входной интервал Y
и Входной интервал X
диапазоны включают заголовки столбцов, то необходимо установить флажок опции Метки
– эти заголовки будут использованы в выходных таблицах, сгенерированных инструментом Регрессия
.
Флажок опции Константа - ноль
следует установить, если в уравнении регрессии константа b
принудительно полагается равной нулю.
Опция Уровень надежности
устанавливается тогда, когда необходимо построить доверительные интервалы для коэффициентов регрессии с доверительным уровнем, отличным от 0.95, который используется по умолчанию. После установки флажка опции Уровень надежности
становится доступным поле ввода, в котором вводится новое значение доверительного уровня.
В области Остатки
имеются четыре опции: Остатки
, Стандартизованные остатки
, График остатков
и График подбора
. Если установлена хотя бы одна из них, то в выходных результатах появится таблица Вывод остатка
, в которой будут выведены значения функции регрессии и остатки – разности между исходными значениями переменной Y и вычисленными значениями функции регрессии. В области Нормальная вероятность
имеется одна опция – ; ее установка порождает в выходных результатах таблицу Вывод вероятности
и приводит к построению соответствующего графика.
7.5. Установите параметры в соответствии с рисунком. Проверьте, что в качестве величины Y указана первая переменная (включая ячейку с названием), и в качестве величины X указаны две остальные переменные (включая ячейки с названиями). Нажмите OK .


7.6. В таблице Регрессионная статистика приводятся следующие данные.
Множественный R – корень из коэффициента детерминации R 2 , приведенного в следующей строке. Другое название этого показателя – индекс корреляции, или множественный коэффициент корреляции.
R-квадрат – коэффициент детерминации R 2 ; вычисляется как отношение регрессионной суммы квадратов (ячейка С12) к полной сумме квадратов (ячейка С14).
Нормированный R-квадрат вычисляется по формуле
где n – количество значений переменной Y, k – количество столбцов во входном интервале переменной X.
Стандартная ошибка – корень из остаточной дисперсии (ячейка D13).
Наблюдения – количество значений переменной Y.
7.7. В Дисперсионной таблице в столбце SS приводятся суммы квадратов, в столбце df – число степеней свободы. в столбце MS – дисперсии. В строке Регрессия в столбце f вычислено значение критериальной статистики для проверки значимости регрессии. Это значение вычисляется как отношение регрессионной дисперсии к остаточной (ячейки D12 и D13). В столбце Значимость F вычисляется вероятность полученного значения критериальной статистики. Если эта вероятность меньше, например, 0.05 (заданного уровня значимости), то гипотеза о незначимости регрессии (т.е. гипотеза о том, что все коэффициенты функции регрессии равны нулю) отвергается и считается, что регрессия значима. В данном примере регрессия незначима.
7.8. В следующей таблице, в столбце Коэффициенты
, записаны вычисленные значения коэффициентов функции регрессии, при этом в строке Y-пересечение
записано значение свободного члена b
. В столбце Стандартная ошибка
вычислены среднеквадратические отклонения коэффициентов.
В столбце t-статистика
записаны отношения значений коэффициентов к их среднеквадратическим отклонениям. Это значения критериальных статистик для проверки гипотез о значимости коэффициентов регрессии.
В столбце P-Значение
вычисляются уровни значимости, соответствующие значениям критериальных статистик. Если вычисленный уровень значимости меньше заданного уровня значимости (например, 0.05). то принимается гипотеза о значимом отличии коэффициента от нуля; в противном случае принимается гипотеза о незначимом отличии коэффициента от нуля. В данном примере только коэффициент b
значимо отличается от нуля, остальные – незначимо.
В столбцах Нижние 95%
и Верхние 95%
приводятся границы доверительных интервалов с доверительным уровнем 0.95. Эти границы вычисляются по формулам
Нижние 95% = Коэффициент - Стандартная ошибка * t α
;
Верхние 95% = Коэффициент + Стандартная ошибка * t α
.
Здесь t α
– квантиль порядка α
распределения Стьюдента с (n-k-1) степенью свободы. В данном случае α
= 0.95. Аналогично вычисляются границы доверительных интервалов в столбцах Нижние 90.0%
и Верхние 90.0%
.
7.9. Рассмотрим таблицу Вывод остатка из выходных результатов. Эта таблица появляется в выходных результатах только тогда, когда установлена хотя бы одна опция в области Остатки диалогового окна Регрессия .

В столбце Наблюдение
приводятся порядковые номера значений переменной Y
.
В столбце Предсказанное Y
вычисляются значения функции регрессии у i = f(х i) для тех значений переменной X
, которым соответствует порядковый номер i
в столбце Наблюдение
.
В столбце Остатки
содержатся разности (остатки) ε i =Y-у i , а в столбце Стандартные остатки
– нормированные остатки, которые вычисляются как отношения ε i / s ε . где s ε – среднеквадратическое отклонение остатков. Квадрат величины s ε вычисляется по формуле
![]()
где – среднее остатков. Величину можно вычислить как отношение двух значений из дисперсионной таблицы: суммы квадратов остатков (ячейка С13) и степени свободы из строки Итого (ячейка В14).
7.10. По значениям таблицы Вывод остатка строятся два типа графиков: графики остатков и графики подбора (если установлены соответствующие опции в области Остатки диалогового окна Регрессия ). Они строятся для каждого компонента переменной X в отдельности.
На графиках остатков отображаются остатки, т.е. разности между исходными значениями Y и вычисленными по функции регрессии для каждого значения компонента переменной X .

На графиках подбора отображаются как исходные значения Y, так и вычисленные значения функции регрессии для каждого значения компонента переменной X .

7.11. Последней таблицей выходных результатов является таблица Вывод вероятности
. Она появляется, если в диалоговом окне Регрессия
установлена опция График нормальной вероятности
.
Значения в столбце Персентиль
вычисляются следующим образом. Вычисляется шаг h = (1/n)*100%
, первое значение равно h/2
, последнее равно 100-h/2
. Начиная со второго значения каждое последующее значение равно предыдущему, к которому прибавлен шаг h
.
В столбце Y
приведены значения переменной Y
, упорядоченные по возрастанию. По данным этой таблицы строится так называемый график нормального распределения
. Он позволяет визуально оценить степень линейности зависимости между переменными X
и Y
.
8. Дисперсионный анализ
8.1. Пакет анализа
позволяет провести три вида дисперсионного анализа. Выбор конкретного инструмента определяется числом факторов и числом выборок в исследуемой совокупности данных.
используется для проверки гипотезы о сходстве средних значений двух или более выборок, принадлежащих одной и той же генеральной совокупности.
Двухфакторный дисперсионный анализ с повторениями
представляет собой более сложный вариант однофакторного анализа, включающий более чем одну выборку для каждой группы данных.
Двухфакторный дисперсионный анализ без повторения
представляет собой двухфакторный анализ дисперсии, не включающий более одной выборки на группу. Он используется для проверки гипотезы о том, что средние значения двух или нескольких выборок одинаковы (выборки принадлежат одной и той же генеральной совокупности).
8.2. Однофакторный дисперсионный анализ
8.2.1. Подготовим данные для анализа. Создайте новый лист и скопируйте на него колонки A, B, C, D . Удалите первые две строки. Подготовленные данные можно использовать для проведения Однофакторного дисперсионного анализа.


8.2.2. Вызовите инструмент создания выборки через Данные> Анализ данных> Однофакторный дисперсионный анализ. Заполните в соответствии с рисунком. Нажмите OK .


8.2.3. Рассмотрим таблицу Итоги : Счет – число повторений, Сумма – сумма значений показателя по строкам, Дисперсия – частная дисперсия показателя.
8.2.4. Таблица Дисперсионный анализ : первая колонка Источник вариации содержит наименование дисперсий, SS – сумма квадратов отклонений, df – степень свободы, MS – средний квадрат, F-критерий фактического F распределения. P-значение – вероятность того, что дисперсия, воспроизводимая уравнением, равна дисперсии остатков. Оно устанавливает вероятность того, что полученная количественная определенность взаимосвязи между факторами и результатом может считаться случайной. F-критическое – это значение F теоретического, которое впоследствии сравнивается с F фактическим.
8.2.5. Нулевая гипотеза о равенстве математических ожиданий всех выборок принимается, если выполняется неравенство F-критерий < F-критическое . эту гипотезу следует отвергнуть. В данном случае средние значения выборок – значимо различаются.
Попробуем для начала найти ответ на каждый из обозначенных нами вопросов в ситуации, когда наша каузальная модель содержит всего две независимые переменные.
Множественная корреляция R и коэффициент детерминация R2
Для оценки совокупной связи всех независимых переменных с зависимой переменной используется множественный коэффициент корреляции R. Отличие коэффициента множественной корреляции R от бивариативного коэффициента корреляции г заключается в том, что он может быть лишь положительным. Для двух независимых переменных он может быть оценен следующим образом:
Коэффициент множественной корреляции может быть определен и в результате оценки частных коэффициентов регрессии, составляющих уравнение (9.1). Для двух переменных это уравнение, очевидно, примет следующий вид:
![]() (9.2)
(9.2)
Если наши независимые переменные будут трансформированы в единицы стандартного нормального распределения, или Z-распределения, уравнение (9.2), очевидно, примет следующий вид:
![]() (9.3)
(9.3)
В уравнении (9.3) коэффициент β обозначает стандартизированное значение коэффициента регрессии В.
Сами стандартизированные коэффициенты регрессии могут быть вычислены по следующим формулам:
Теперь формула для вычисления коэффициента множественной корреляции будет выглядеть так:
![]()
Еще одним способом оценки коэффициента корреляции R является вычисление бивариативного коэффициента корреляции r между значениями зависимой переменной У и соответствующими им значениями , вычисленными на основании уравнения линейной регрессии (9.2). Иными словами, величина R может быть оценена следующим образом:
Наряду с этим коэффициентом мы можем оценить, как и в случае простой регрессии, величину R 2, которую принято еще обозначать как коэффициент детерминации. Так же как и в ситуации оценки связи между двумя переменными, коэффициент детерминации R 2 показывает, какой процент дисперсии зависимой переменной Y , т.е. , оказывается связанным с дисперсией всех независимых переменных – . Иными словами, оценка коэффициента детерминации может быть осуществлена следующем образом:
Также мы можем оценить процент остаточной дисперсии зависимой переменной, нс связанный ни с одной из независимых переменных 1 – R 2. Квадратный корень от этой величины, т.е. величина , так же, как и в случае бивариативной корреляции, называют коэффициентом отчуждения.
Корреляция части
Коэффициент детерминация R 2 демонстрирует, какой процент дисперсии зависимой переменной может быть связан с дисперсией всех независимых переменных, включенных в каузальную модель. Чем больше этот коэффициент, тем более значимой является выдвинутая нами каузальная модель. Если этот коэффициент оказывается не слишком большим, то и вклад исследуемых нами переменных в общую дисперсию зависимой переменной также оказывается незначительным. На практике, однако, часто требуется не только оценить совокупный вклад всех переменных, но и отдельный вклад каждой из рассматриваемых нами независимых переменных. Такой вклад может быть определен как корреляция части.
Как мы знаем, в случае бивариативной корреляции процент дисперсии зависимой переменной, связанный с дисперсией независимой переменной, может быть обозначен как r 2. Однако часть этой дисперсии в случае исследования эффектов нескольких независимых переменных оказывается обусловлена одновременно дисперсией независимой переменной, которую мы используем в качестве контрольной. Наглядно эти соотношения показаны на рис. 9.1.

Рис. 9.1. Соотношение дисперсий зависимой (Y ) и двух независимых (X 1 и Х 2) переменных в корреляционном анализе с двумя независимыми переменными
Как показано на рис. 9.1, вся дисперсия Y , связанная с двумя нашими независимыми переменными, состоит из трех частей, обозначенными а, b и с. Части а и b дисперсии Y принадлежат по отдельности дисперсии двух независимых переменных – Х 1 и Х 2. В то же время дисперсия части с одновременно связывает и дисперсию зависимой переменной У, и дисперсию двух наших переменных X. Следовательно, для того чтобы оценить связь переменной X 1 с переменной Y, которая не обусловлена влиянием переменной Х 2 на переменную Y , необходимо из величины R" 2 вычесть величину квадрата корреляции Y с Х 2:
![]() (9.6)
(9.6)
Аналогичным образом можно оценить часть корреляции У с Х 2, которая не обусловлена ее корреляцией с Х 1.
![]() (9.7)
(9.7)
Величина sr в уравнениях (9.6) и (9.7) и есть искомая нами корреляция части.
Определить корреляцию части можно также и в терминах обычной бивариативной корреляции:

По-другому корреляция части называется полупарциальной корреляцией. Это название означает, что при расчете корреляции эффект второй независимой переменной устраняется применительно к значениям первой независимой переменной, но нс устраняется по отношению к зависимой переменной. Эффект Х 1 как бы корректируется с помощью значений Х 2, так что коэффициент корреляции рассчитывается не между Y и X 1 а между Y и , причем значения рассчитываются на основе значений Х 2 так, как было рассмотрено в главе, посвященной простой линейной регрессии (см. подпараграф 7.4.2). Таким образом, оказывается справедливым следующее соотношение:
Для того чтобы оценить корреляцию одной независимой переменной с зависимой переменной в отсутствие влияния других независимых переменных как на саму независимую переменную, так и на зависимую переменную, в регрессионном анализе используется понятие частной корреляции.
Частные корреляции
Частная, или парциальная, корреляция определяется в математической статистике через пропорцию дисперсии зависимой переменной, связанной с дисперсией данной независимой переменной, по отношению ко всей дисперсии этой зависимой переменной, не считая той ее части, которая связана с дисперсией других независимых переменных. Формально для случая двух независимых переменных это можно выразить следующим образом:

Сами значения частной корреляции рr могут быть найдены на основе значений бивариативной корреляции:

Частная корреляция, таким образом, может быть определена как обычная бивариативная корреляция между скорректированными значениями как зависимой, так и независимой переменной. Непосредственно коррекция осуществляется в соответствии со значениями независимой переменной, выступающей в качестве контрольной. Иными словами, частная корреляция между зависимой переменной Y и независимой переменной X i может быть определена как обычная корреляция между значениями и значениями , причем значения и предсказываются на основе значений второй независимой переменной Х 2.



